To avoid skewness, try to select a Primary Index which has as many unique values as possible. PI columns like month, day, etc. will have very few unique values. So during data distribution only a few amps will hold all the data resulting in skew..
Moreover, what is skew in Teradata?
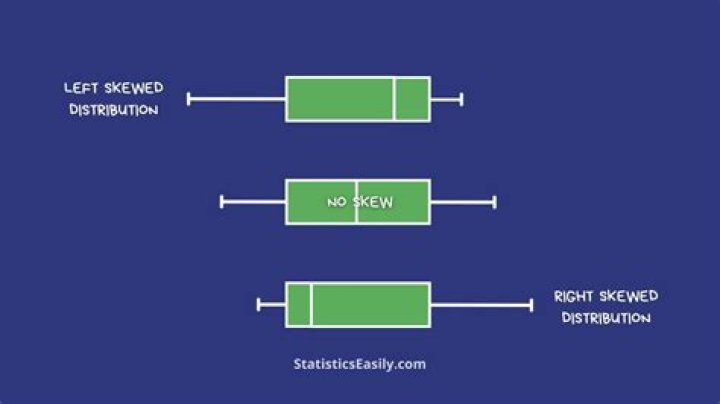
Skewness in Teradata. Definition. Skewness is the statistical term, which refers to the row distribution on AMPs. If the data is highly skewed, it means some AMPs are having more rows and some very less i.e. data is not properly/evenly distributed. This affects the performance/Teradata's parallelism.
Similarly, what is Table skew? The Table Skew dialog searches for databases in the system that have an uneven data distribution (or skew) based on a spread threshold. These data slices and the SPUs that manage them become a performance bottleneck for your queries. Uneven distribution of data is called skew. An optimal table distribution has no skew.
Likewise, people ask, what is CPU skew in Teradata?
CPU skew occurs when the work to execute a query is not distributed evenly among the segments. The CPU metric is the average of the CPU percentages used by each process executing the query.
What is AMP in Teradata?
DEFINITION. AMP, acronym for "Access Module Processor," is the type of vproc (Virtual Processor) used to manage the database, handle file tasks and and manipulate the disk subsystem in the multi-tasking and possibly parallel-processing environment of the Teradata Database.
Related Question Answers
What is acceptable skew factor in Teradata?
Skewness: Skewness is the statistical term, which refers to the row distribution on AMPs. If the data is highly skewed, it means some AMPs are having more rows and some very less i.e. data is not properly/evenly distributed. Percentage of skewness is called skew factor. 30% skew factor is acceptable.What is skew factor?
27 Aug 2008. Hello,Skewness is the statistical term, which refers to the row distribution on AMPs. If the data is highly skewed, it means some AMPs are having more rows and some very less i.e. data is not properly/evenly distributed. This affects the performance/Teradata's parallelism.What is skew in redshift?
Redshift Table Data Skew and How to avoid it. When you create a table and then load the data into the system, the rows of the table should be distributed uniformly among all the data nodes slice. If some data node slices have more rows of a table than others, this scenarios is called skew.Is bynet a hardware or software?
The BYNET is the combination of hardware and software that enables the high speed communication inside and between the nodes.How is data stored in Teradata?
Data on the Teradata DBS is stored in relational databases. Think of a relational database as a collection of data organized into one or more tables. A table represents data in two dimensions: vertical columns and horizontal rows. When you create a table, you give it a name.What is spool space in Teradata?
Spool is temporary disk space used to hold intermediate rows during query processing, and to hold the rows in the answer set of a transaction. Spool space is allocated to a user as a total amount available for that user, however this total amount is spread across all AMPS.What is the use of bynet in Teradata?
Message Passing Layer − Message Passing Layer called as BYNET, is the networking layer in Teradata system. It allows the communication between PE and AMP and also between the nodes. It receives the execution plan from Parsing Engine and sends to AMP.What is main feature of the Teradata database?
Main Features of Teradata Database With linear scalability (Software can scale linearly with hardware), unconditional parallelism, multi-faceted parallelism, intelligent data distribution, parallel-aware optimizer makes Teradata is capable of handling large data and complex queries.Is Teradata a distributed database?
Hadoop is a Big data technology, which is used to store the very large amount of data in a distributed fashion among the nodes, whereas Teradata is Relational database warehouse implemented in single RDBMS which acts as a center repository.What is meant by Teradata?
Teradata is massively parallel open processing system for developing large-scale data warehousing applications. Teradata is an open system. This tool provides support to multiple data warehouse operations at the same time to different clients.How many types of nodes are there in Teradata?
There are two types of nodes in an Aster instance: queen nodes and vWorker nodes. For more information about the Aster instance architecture, refer to the Teradata Aster® Execution Engine Aster Instance User Guide .What is MPP architecture?
MPP (massively parallel processing) is the coordinated processing of a program by multiple processors working on different parts of the program. Each processor has its own operating system and memory. MPP speeds the performance of huge databases that deal with massive amounts of data.