What is Kafka CDC?
.
Subsequently, one may also ask, what is database CDC?
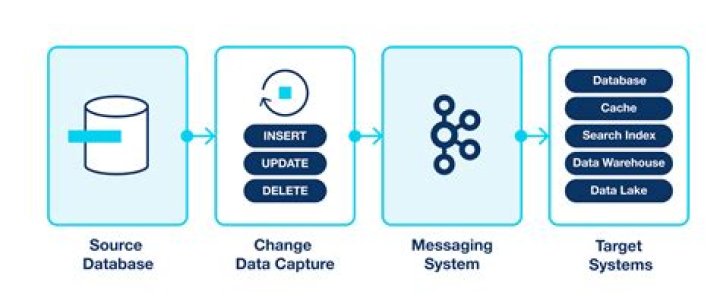
In databases, change data capture (CDC) is a set of software design patterns used to determine (and track) the data that has changed so that action can be taken using the changed data.
Likewise, what Kafka streams? Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka's server-side cluster technology.
Simply so, can Kafka be used as a database?
Kafka is often used to capture and distribute a stream of database updates (this is often called Change Data Capture or CDC). Applications that consume this data in steady state just need the newest changes, however new applications need start with a full dump or snapshot of data.
How does change data capture work?
Change data capture refers to the process or technology for identifying and capturing changes made to a database. Those changes can then be applied to another data repository or made available in a format consumable by ETL, EAI, or other types of data integration tools.
Related Question AnswersWhat is CDC process?
Change data capture (CDC) is the process of capturing changes made at the data source and applying them throughout the enterprise. CDC minimizes the resources required for ETL ( extract, transform, load ) processes because it only deals with data changes. The goal of CDC is to ensure data synchronicity.Is CDC a database?
The CDC Prevention Guidelines Database The Prevention Guidelines Database is a comprehensive compendium of all of the official guidelines and recommendations published by the US Centers for Disease Control and Prevention (CDC) for the prevention of diseases, injuries, and disabilities.What is CDC replication?
IBM® IBM Data Replication - CDC Replication is a replication solution that captures database changes as they happen and delivers them to target databases, message queues, or an ETL solution such as IBM DataStage® based on table mappings configured in the IBM Data Replication Management Console GUI application.What does the CDC do?
The Centers for Disease Control and Prevention (CDC) serves as the national focus for developing and applying disease prevention and control, environmental health, and health promotion and health education activities designed to improve the health of the people of the United States.How does CDC work in Oracle?
Change Data Capture efficiently identifies and captures data that has been added to, updated, or removed from, Oracle relational tables, and makes the change data available for use by applications. Change Data Capture is provided as an Oracle database server component with Oracle9i.What is CDC in Oracle?
Oracle CDC. Oracle CDC, or Oracle change data capture, is a technology used for detecting and capturing insertions, updates, and deletions that are applied to tables in an Oracle database.What is CDC SSIS?
Combining CDC and SSIS for Incremental Data Loads. The change data capture (CDC) feature introduced in SQL Server 2008 provides an efficient framework for tracking inserts, updates, and deletes in tables in a SQL Server database.What is IBM CDC tool?
Change Data Capture (CDC) is a replication solution that captures database changes as they happen and delivers them to target databases, message queues, or an extract, transform, load (ETL) solution such as InfoSphere® DataStage® based on table mappings that are configured in the Management Console graphical userWhat database does Kafka use?
Apache Kafka. Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.Why is Kafka so fast?
Kafka relies on the filesystem for the storage and caching. The problem is disks are slower than RAM. This is because the seek-time through a disk is large compared to the time required for actually reading the data. Modern operating systems allocate most of their free memory to disk-caching.How long does Kafka store data?
The Kafka cluster retains all published messages—whether or not they have been consumed—for a configurable period of time. For example if the log retention is set to two days, then for the two days after a message is published it is available for consumption, after which it will be discarded to free up space.How does Kafka store data?
Kafka wraps compressed messages together Producers sending compressed messages will compress the batch together and send it as the payload of a wrapped message. And as before, the data on disk is exactly the same as what the broker receives from the producer over the network and sends to its consumers.Is Kafka asynchronous?
By default, topics in Kafka are retention based: messages are retained for some configurable amount of time. It's worth noting that this is an asynchronous process, so a compacted topic may contain some superseded messages, which are waiting to be compacted away. Compacted topics let us make a couple of optimisations.How does Kafka work?
How does it work? Applications (producers) send messages (records) to a Kafka node (broker) and said messages are processed by other applications called consumers. Said messages get stored in a topic and consumers subscribe to the topic to receive new messages.Is Kafka an acid?
The Metamorphosis of Kafka So with a lot of help from stream-processing algorithms, Kleppmann concludes Kafka can indeed be ACID compliant. This gives new confidence in the integrity of Kafka-managed data and effectiveness of downstream usage.How much memory does Kafka need?
RAM: In most cases, Kafka can run optimally with 6 GB of RAM for heap space. For especially heavy production loads, use machines with 32 GB or more. Extra RAM will be used to bolster OS page cache and improve client throughput.Where is database stored?
Database tables and indexes may be stored on disk in one of a number of forms, including ordered/unordered flat files, ISAM, heap files, hash buckets, or B+ trees. Each form has its own particular advantages and disadvantages. The most commonly used forms are B+ trees and ISAM.Why would I use Kafka?
Kafka is used for real-time streams of data, to collect big data, or to do real time analysis (or both). Kafka is used with in-memory microservices to provide durability and it can be used to feed events to CEP (complex event streaming systems) and IoT/IFTTT-style automation systems.How do I use Kafka to stream data?
This quick start follows these steps:- Start a Kafka cluster on a single machine.
- Write example input data to a Kafka topic, using the so-called console producer included in Kafka.
- Process the input data with a Java application that uses the Kafka Streams library.