[ max_features ] is the size of the random subsets of features to consider when splitting a node. So max_features is what you call m. When max_features="auto" , m = p and no feature subset selection is performed in the trees, so the "random forest" is actually a bagged ensemble of ordinary regression trees..
Hereof, what is N_estimators in random forest?
n_estimators : This is the number of trees you want to build before taking the maximum voting or averages of predictions. Higher number of trees give you better performance but makes your code slower.
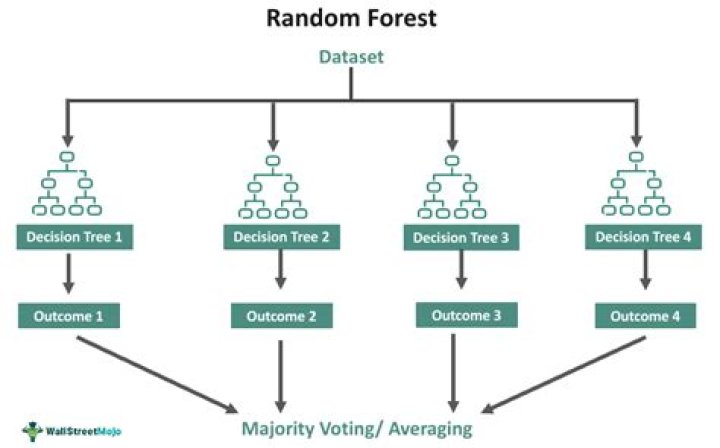
what does a random forest do? Random forests or random decision forests are an ensemble learning method for classification, regression and other tasks that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual
Beside this, what are Hyperparameters in random forest?
In the case of a random forest, hyperparameters include the number of decision trees in the forest and the number of features considered by each tree when splitting a node. (The parameters of a random forest are the variables and thresholds used to split each node learned during training).
What causes random forest to Overfit the data?
The hyper parameter when increased may cause random forest to over fit the data is the Depth of a tree. Over fitting occurs only when the depth of the tree is increased. Under fitting can also be caused due to increase in the number of trees.
Related Question Answers
Does Random Forest Overfit?
Random Forests does not overfit. The testing performance of Random Forests does not decrease (due to overfitting) as the number of trees increases. Hence after certain number of trees the performance tend to stay in a certain value.How do you increase the accuracy of a random forest?
Now we'll check out the proven way to improve the accuracy of a model: - Add more data. Having more data is always a good idea.
- Treat missing and Outlier values.
- Feature Engineering.
- Feature Selection.
- Multiple algorithms.
- Algorithm Tuning.
- Ensemble methods.
How do I stop Overfitting random forest?
1 Answer - n_estimators: The more trees, the less likely the algorithm is to overfit.
- max_features: You should try reducing this number.
- max_depth: This parameter will reduce the complexity of the learned models, lowering over fitting risk.
- min_samples_leaf: Try setting these values greater than one.
Is random forest black box?
Random forest as a black box Indeed, a forest consists of a large number of deep trees, where each tree is trained on bagged data using random selection of features, so gaining a full understanding of the decision process by examining each individual tree is infeasible.How probabilities are calculated in random forest?
In Random Forest package by passing parameter “type = prob” then instead of giving us the predicted class of the data point we get the probability. How is this probability get calculated? By default, random forest does majority voting among all its trees to predict the class of any data point.Why is random forest good?
Random forests is great with high dimensional data since we are working with subsets of data. It is faster to train than decision trees because we are working only on a subset of features in this model, so we can easily work with hundreds of features.How many trees are there in a random forest?
64 - 128 trees
What is entropy in decision tree?
Entropy : A decision tree is built top-down from a root node and involves partitioning the data into subsets that contain instances with similar values (homogeneous). ID3 algorithm uses entropy to calculate the homogeneity of a sample.What is the final objective of decision tree?
As the goal of a decision tree is that it makes the optimal choice at the end of each node it needs an algorithm that is capable of doing just that. That algorithm is known as Hunt's algorithm, which is both greedy, and recursive.What is random state?
Random state ensures that the splits that you generate are reproducible. Scikit-learn uses random permutations to generate the splits. The random state that you provide is used as a seed to the random number generator. This ensures that the random numbers are generated in the same order.How does random forest work?
The random forest is a classification algorithm consisting of many decisions trees. It uses bagging and feature randomness when building each individual tree to try to create an uncorrelated forest of trees whose prediction by committee is more accurate than that of any individual tree.What is Max_depth?
max_depth: The max_depth parameter specifies the maximum depth of each tree. The default value for max_depth is None, which means that each tree will expand until every leaf is pure. A pure leaf is one where all of the data on the leaf comes from the same class.Does random forest need cross validation?
2 Answers. Yes, out-of-bag performance for a random forest is very similar to cross validation. That being said, the no of trees and no of variables are reasonably easy to fix, so random forest is one of the models I consider with sample sizes that are too small for data-driven model tuning.What is Random_state in random forest?
The interface documentation specifically states: If int, random_state is the seed used by the random number generator; If RandomState instance, random_state is the random number generator; If None, the random number generator is the RandomState instance used by np. random.What is the grid search technique?
Grid Search. Grid search is a technique which tends to find the right set of hyperparameters for the particular model. Hyperparameters are not the model parameters and it is not possible to find the best set from the training data.What are Hyperparameters in machine learning?
In machine learning, a hyperparameter is a parameter whose value is set before the learning process begins. Given these hyperparameters, the training algorithm learns the parameters from the data.What is N_estimators?
After reading the documentation for RandomForest Regressor you can see that n_estimators is the number of trees to be used in the forest. Since Random Forest is an ensemble method comprising of creating multiple decision trees, this parameter is used to control the number of trees to be used in the process.Where is random forest used?
Random forest algorithm can be used for both classifications and regression task. It provides higher accuracy. Random forest classifier will handle the missing values and maintain the accuracy of a large proportion of data. If there are more trees, it won't allow overfitting trees in the model.Is Xgboost better than random forest?
Folks know that gradient-boosted trees generally perform better than a random forest, although there is a price for that: GBT have a few hyperparams to tune, while random forest is practically tuning-free. Let's look at what the literature says about how these two methods compare.